안녕하세요! 서당개입니다. ^^
오늘은 머신러닝 모델들에 대해 완~전 처음부터 최신 모델까지 싹 다 정리해볼게요 ^^
저도 공부하면서 정말 헷갈렸던 부분들이 많았는데요, 특히 "이 모델은 언제 쓰는 거야?", "왜 이렇게 작동하는 거지?" 같은 의문이 많았거든요. 그래서 이번 글에서는 각 모델의 원리와 수식, 그리고 실제로 어떤 상황에서 쓰면 좋은지까지 전부 다뤄볼 거예요!
그럼 지금부터 본격적으로 파헤쳐 봅시다!
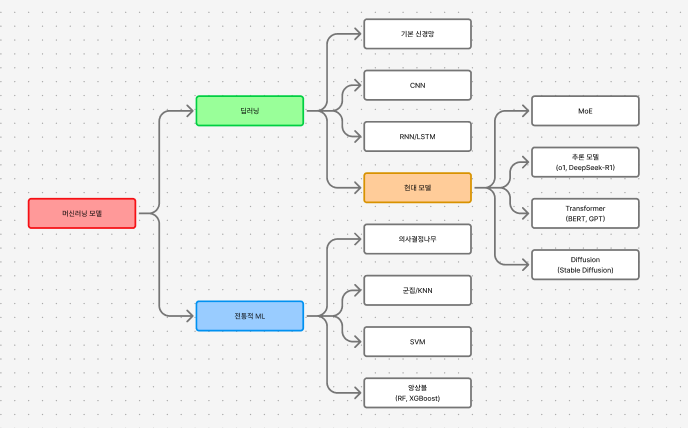
1. 전통적 머신러닝 모델들
1-1. 의사결정나무 (Decision Tree)
의사결정나무는 말 그대로 나무처럼 생긴 구조로 데이터를 분류하거나 예측하는 모델이에요. 마치 스무고개 게임처럼 질문을 계속 던지면서 답을 찾아가는 방식이죠!
원리와 작동 방식
의사결정나무의 핵심은 데이터를 어떻게 잘 나눌 것인가예요. 이 때 사용하는 게 바로 지니 불순도(Gini Impurity)나 엔트로피(Entropy) 같은 지표들이에요.
지니 불순도는 값이 작을수록 데이터가 잘 분리된 거에요.
예를 들어, 한 노드에 개만 100마리 있으면 지니 불순도는 0이 돼요 (완벽하게 순수!).
반대로 개 50마리, 고양이 50마리가 섞여 있으면 0.5가 되죠.
엔트로피 방식도 있는데요, 이건 정보 이론에서 나온 개념이에요.
둘 다 결국 "얼마나 깔끔하게 분리되었는가"를 측정하는 거예요.
의사결정나무는 이 불순도를 최대한 낮추는 방향으로 계속 가지를 쳐나가요.
장점
의사결정나무의 가장 큰 장점은 해석이 진짜 쉽다는 거예요! 비전공자한테도 "이 조건이면 이렇게 되고, 저 조건이면 저렇게 된다"고 설명하기가 너무 편하죠. 또 데이터 전처리가 거의 필요 없어요. 정규화? 스케일링? 그런 거 안 해도 되요!
단점
하지만... 치명적인 단점이 있어요. 바로 과적합(Overfitting)이요 ㅠㅠ 트리가 너무 깊어지면 훈련 데이터에만 완벽하게 맞춰져서 새로운 데이터는 제대로 예측 못 하는 경우가 많아요. 그래서 실무에서 의사결정나무를 단독으로 쓰는 경우는 거의 없고요, 다음에 나올 앙상블 기법으로 여러 개를 합쳐서 사용해요.
언제 쓰면 좋을까?
의사결정나무는 빠른 프로토타입이 필요할 때, 혹은 결과를 설명해야 하는 비즈니스 환경에서 좋아요. 예를 들어 "고객이 이탈할 것 같은 이유"를 경영진에게 보고해야 한다면? 의사결정나무가 딱이죠!
1-2. 앙상블 모델 - 집단 지성의 힘!
Random Forest (랜덤 포레스트)
랜덤 포레스트는 의사결정나무를 여러 개 만들어서 투표로 결정하는 방식이에요. 일종의 민주주의 같은 거죠! 이 방식을 배깅(Bagging, Bootstrap Aggregating)이라고 불러요.
작동 원리는 요렇게 돼요. 먼저 원본 데이터에서 복원 추출(같은 데이터를 여러 번 뽑을 수 있음)로 여러 개의 샘플을 만들어요. 각 샘플마다 의사결정나무를 하나씩 만들죠. 그리고 각 트리가 분기할 때 전체 특성 중에서 랜덤하게 일부만 골라서 사용해요. 최종 예측은 모든 트리의 투표로 결정되고요!
왜 이게 잘 작동하느냐? 각 트리는 조금씩 다른 실수를 하는데, 이 실수들이 투표를 통해 서로 상쇄되기 때문이에요. 수학적으로 보면 분산(Variance)을 크게 줄여주는 효과가 있어요.
랜덤 포레스트의 장점은 과적합이 거의 없다는 거예요! 단일 트리보다 훨씬 안정적이죠. 그리고 특성 중요도(Feature Importance)를 쉽게 구할 수 있어서 "어떤 변수가 제일 중요한가?"를 알 수 있어요.
단점은... 트리가 수백 개씩 만들어지다 보니 해석이 어려워진다는 거예요. 그리고 예측 시간도 좀 오래 걸리고요.
XGBoost (eXtreme Gradient Boosting)
XGBoost는 요즘 캐글 대회에서 거의 필수로 쓰이는 모델이에요! 이건 부스팅(Boosting) 방식을 사용하는데요, 배깅과는 다르게 트리를 순차적으로 만들어요.
작동 원리가 진짜 똑똑해요. 첫 번째 트리로 예측을 하면 당연히 오차가 있겠죠? 그럼 두 번째 트리는 그 오차를 예측하도록 학습해요. 세 번째 트리는 또 남은 오차를 예측하고... 이렇게 계속 오차를 줄여나가는 거예요!
수학적으로는 경사 하강법(Gradient Descent)을 사용해요. 손실 함수를 최소화하는 방향으로 계속 트리를 추가하는 거죠.
학습률은 보통 0.01~0.3 정도로 작게 설정해요. 너무 크면 과적합되고, 너무 작으면 학습이 느려지거든요.
XGBoost의 특별한 점은 정규화(Regularization) 항이 내장되어 있다는 거예요. 이게 있어서 과적합을 막아주죠!
장점이 엄청 많아요. 예측 성능이 진짜 좋고, 병렬 처리로 학습 속도도 빠르고, 결측치도 자동으로 처리해주고, 중요 특성도 알려주고... 완전 만능이에요!
단점은 하이퍼파라미터 튜닝이 까다롭다는 거예요. learning_rate, max_depth, n_estimators, subsample 등등 조정할 게 너무 많아서 초보자는 헤매기 쉬워요. 그리고 랜덤 포레스트보다는 과적합 위험이 조금 더 있어요.
언제 쓸까? 정형 데이터(테이블 형태의 데이터)에서는 거의 XGBoost가 답이에요. 특히 캐글 대회에서 상위권 솔루션 보면 XGBoost나 LightGBM이 거의 필수로 들어가 있어요!
1-3. 서포트 벡터 머신 (SVM)
SVM은 2000년대 초중반에 진짜 인기가 많았던 모델이에요. 요즘은 딥러닝에 밀렸지만, 작은 데이터셋에서는 여전히 강력하죠!
원리와 작동 방식
SVM의 핵심 아이디어는 두 클래스를 가장 잘 구분하는 초평면(Hyperplane)을 찾는 거예요. 그냥 구분만 하는 게 아니라, 두 클래스 사이의 마진(Margin)을 최대화하는 초평면을 찾죠.
커널 트릭 (Kernel Trick)
SVM의 진짜 강점은 바로 커널 트릭이에요! 선형으로 분리 안 되는 데이터를 고차원으로 매핑해서 분리 가능하게 만드는 거죠.
대표적인 커널들이 있어요:
- RBF(Radial Basis Function) 커널
- 다항식 커널
RBF 커널이 제일 많이 쓰이는데요, gamma 값이 클수록 결정 경계가 복잡해져요. 작으면 단순해지고요.
장점과 단점
SVM의 장점은 고차원 데이터에서도 잘 작동한다는 거예요. 특히 샘플 수보다 특성 수가 많을 때도 괜찮아요. 그리고 이론적 기반이 탄탄해서 신뢰할 수 있죠.
단점은... 데이터가 많으면 진짜 느려요 ㅠㅠ 10만 개 이상 되면 거의 못 쓸 정도예요. 그리고 하이퍼파라미터 튜닝(C, gamma, kernel 선택 등)이 까다로워요.
언제 쓸까? 데이터가 수천~수만 개 정도로 적당하고, 특성이 많은 경우에 좋아요. 예를 들어 텍스트 분류, 이미지 분류(딥러닝 이전 시대), 바이오인포매틱스 데이터 분석 등에서 쓰여요.
1-4. 군집(Clustering)과 최근접 이웃(KNN)
K-Means 군집
K-Means는 비지도 학습의 대표 주자예요! 레이블 없이 데이터를 K개의 그룹으로 나누는 거죠.
알고리즘은 진짜 직관적이에요. 먼저 K개의 중심점(Centroid)을 랜덤하게 초기화해요. 그 다음 각 데이터를 가장 가까운 중심점에 할당하고요. 그럼 각 그룹의 평균을 구해서 중심점을 업데이트해요. 이걸 중심점이 더 이상 안 움직일 때까지 반복하는 거죠!
장점은 구현이 쉽고 빠르다는 거예요. 단점은 K를 미리 정해야 하고, 초기값에 민감하고, 구형(Spherical) 클러스터만 잘 찾는다는 거죠.
DBSCAN
K-Means의 단점을 보완한 게 DBSCAN이에요! 밀도 기반으로 클러스터를 찾아서 모양에 구애받지 않고, K를 미리 정할 필요도 없어요. 게다가 이상치(Outlier)도 자동으로 찾아주죠!
작동 원리는 요래요. 각 점 주변 반경 안에 최소 n개 이상의 점이 있으면 핵심 점(Core Point)으로 분류해요. 핵심 점들끼리 연결된 영역이 하나의 클러스터가 되는 거죠.
언제 쓸까? 고객 세분화, 이상 거래 탐지, 위치 기반 클러스터링 등에 쓰여요. 특히 K-Means가 잘 안 맞는 불규칙한 형태의 클러스터를 찾을 때 좋아요!
K-최근접 이웃 (KNN)
KNN은 진짜 단순무식한 알고리즘이에요. 새로운 데이터가 들어오면 가장 가까운 K개 이웃을 찾아서 다수결로 결정하는 거예요. 학습이라는 게 없어요. 그냥 데이터를 다 저장해뒀다가 예측할 때 거리를 계산하는 거죠.
거리는 보통 유클리드 거리를 써요.
장점은 구현이 진짜 쉽고, 다중 클래스 분류도 자연스럽게 되고, 데이터만 있으면 바로 쓸 수 있다는 거예요.
단점은... 데이터가 많으면 예측이 진짜 느려요! 매번 전체 데이터와 거리를 다 계산해야 하거든요. 그리고 차원이 높으면 차원의 저주로 성능이 떨어져요. 또 특성 스케일링에 민감해서 전처리가 필수예요.
언제 쓸까? 추천 시스템, 패턴 인식, 이상치 탐지 등에 쓰여요. 특히 빠른 프로토타입이 필요하거나 데이터가 별로 없을 때 좋아요.
2. 신경망의 세계
2-1. 기본 신경망 (Neural Network)
드디어 딥러닝의 시작이에요! 인공 신경망은 인간의 뇌를 모방한 모델이에요. 뉴런들이 층층이 쌓여 있는 구조죠.
작동 원리
각 뉴런은 입력 x를 받아서 가중치 w를 곱하고, 편향 b를 더한 다음, 활성화 함수를 통과시켜요.
활성화 함수는 여러 가지가 있어요.
- ReLU - 요즘 가장 많이 씀!
- Sigmoid - 0과 1 사이 값
- Tanh -1과 1 사이 값
학습은 역전파(Backpropagation)로 해요. 출력과 정답의 차이(손실)를 계산하고, 경사 하강법으로 가중치를 업데이트하는 거죠.
장점은 비선형 관계를 학습할 수 있고, 충분한 뉴런과 층이 있으면 어떤 함수도 근사할 수 있다는 거예요 (Universal Approximation Theorem).
단점은 데이터가 많이 필요하고, 과적합되기 쉽고, 블랙박스라서 해석이 어렵다는 거죠.
2-2. 합성곱 신경망 (CNN)
CNN은 이미지 처리의 혁명을 일으켰어요! 2012년 AlexNet이 ImageNet 대회에서 압도적으로 우승하면서 딥러닝 붐이 시작됐죠.
핵심 아이디어
CNN의 핵심은 합성곱(Convolution) 연산이에요. 작은 필터(커널)를 이미지 위에서 슬라이딩하면서 특징을 추출하는 거죠.
예를 들어 3x3 커널로 엣지를 검출할 수 있어요. 층이 깊어질수록 더 복잡한 특징(눈, 코 등)을 학습하죠!
구조는 보통 이래요:
- 합성곱 층: 특징 추출
- 풀링 층: 크기 줄이기 (Max Pooling이 많이 쓰임)
- 완전 연결 층: 최종 분류
장점은 이미지의 공간 구조를 보존하고, 파라미터 공유로 효율적이고, 위치 불변성이 있다는 거예요.
단점은 큰 입력에는 메모리를 많이 먹고, 회전이나 크기 변화에는 여전히 취약해요.
언제 쓸까? 이미지 분류, 객체 탐지, 얼굴 인식, 의료 영상 분석 등 거의 모든 컴퓨터 비전 작업에 쓰여요!
2-3. 순환 신경망 (RNN/LSTM)
RNN은 시퀀스 데이터(시계열, 텍스트 등)를 다루는 모델이에요. 이전 시점의 정보를 기억하면서 다음을 예측하죠.
RNN의 구조
문제는 기울기 소실(Vanishing Gradient) 문제예요. 시퀀스가 길어지면 앞부분의 정보가 사라져버려요 ㅠㅠ
LSTM (Long Short-Term Memory)
이 문제를 해결한 게 LSTM이에요! 세 개의 게이트로 정보 흐름을 조절해요:
- 망각 게이트(Forget Gate): 뭘 잊을지 결정
- 입력 게이트(Input Gate): 새로운 정보를 얼마나 받을지 결정
- 출력 게이트(Output Gate): 뭘 출력할지 결정
수식이 좀 복잡한데요.
복잡해 보이지만, 핵심은 Cell State 를 유지하면서 장기 의존성을 학습한다는 거예요!
언제 쓸까? 기계 번역, 텍스트 생성, 주가 예측, 음성 인식 등에 쓰였어요. 하지만 요즘은 다음에 나올 Transformer에게 밀렸죠...
3. 현대의 최신 모델들
3-1. Transformer - 혁명의 시작
2017년 구글이 발표한 "Attention is All You Need" 논문으로 세상이 바뀌었어요! RNN을 완전히 제거하고 Attention만으로 모델을 만든 거죠.
Self-Attention 메커니즘
Transformer의 핵심은 Self-Attention이에요. 문장 내 모든 단어가 서로를 참고하면서 표현을 만드는 거죠.
설명해볼게요! Query는 "나는 무엇을 찾고 있는가", Key는 "나는 이런 정보를 가지고 있어", Value는 "실제 내용"이라고 생각하면 돼요. Query와 Key의 내적으로 유사도를 구하고, 이를 softmax로 확률로 만든 다음, Value에 곱해서 가중 평균을 구하는 거예요.
Multi-Head Attention
더 똑똑한 건 여러 개의 Attention을 병렬로 돌리는 거예요(보통 8개). 각 헤드는 다른 관점에서 관계를 학습해요. 어떤 헤드는 문법적 관계를, 다른 헤드는 의미적 관계를 학습하는 식이죠!
왜 이게 혁명적이었나?
RNN과 달리 병렬 처리가 가능해요! RNN은 순차적으로 처리해야 해서 느렸는데, Transformer는 모든 단어를 동시에 처리할 수 있어요. 또 장거리 의존성 문제도 없고요. 어떤 단어든 한 번에 참조할 수 있으니까요.
단점은 계산 복잡도가 높아요. 시퀀스 길이가 길어질수록 메모리와 연산이 기하급수적으로 늘어나죠.
BERT와 GPT
Transformer에서 두 거장이 나왔어요.
- BERT: 인코더만 사용, 양방향으로 문맥 학습, 문장 이해에 특화
- GPT: 디코더만 사용, 왼쪽에서 오른쪽으로 학습, 텍스트 생성에 특화
BERT는 마스크된 단어를 예측하는 방식으로 학습하고(Masked Language Model), GPT는 이전 단어들로 다음 단어를 예측하는 방식으로 학습해요. 둘 다 엄청나게 큰 데이터로 사전 학습한 다음, 특정 작업에 파인튜닝해서 써요.
언제 쓸까? 거의 모든 자연어 처리 작업에 쓰여요. 번역, 요약, 질문 답변, 감정 분석, 텍스트 생성 등등. 요즘 ChatGPT나 Claude 같은 거 다 Transformer 기반이에요!
3-2. Diffusion Model - 노이즈에서 이미지로
Diffusion Model은 2020년 이후 이미지 생성 분야를 완전히 장악했어요! Stable Diffusion, DALL-E 2, Midjourney 등이 다 이 기술을 써요.
작동 원리
Diffusion Model의 핵심은 두 단계예요:
- Forward Process (확산): 깨끗한 이미지에 점진적으로 노이즈를 추가해서 완전한 노이즈로 만들어요
- Reverse Process (역확산): 노이즈에서 시작해서 점진적으로 노이즈를 제거해 이미지를 생성해요
왜 GAN보다 좋은가?
GAN은 학습이 불안정하고 mode collapse 문제가 있었어요. Diffusion은 학습이 안정적이고 다양성도 높아요. 대신 샘플링이 느리다는 단점이 있었는데, DDIM이나 다른 기법들로 많이 개선됐어요.
Stable Diffusion
Stable Diffusion의 똑똑한 점은 픽셀 공간이 아니라 Latent Space에서 작동한다는 거예요. VAE로 이미지를 압축한 다음 diffusion을 하니까 계산이 훨씬 빨라졌죠!
그리고 텍스트 조건을 주려면 CLIP이나 T5 같은 텍스트 인코더를 써요. 텍스트를 임베딩으로 바꾼 다음 cross-attention으로 diffusion process에 주입하는 거죠.
언제 쓸까? 텍스트-이미지 생성, 이미지 편집, 초해상도, 인페인팅 등 거의 모든 이미지 생성 작업에 쓰여요. 예술 창작, 디자인, 게임 개발 등에서 활용되고 있죠!
3-3. MoE (Mixture of Experts) - 전문가들의 협업
MoE는 최신 LLM들이 크기를 키우면서도 효율성을 유지하는 비결이에요! GPT-4, Mixtral, DeepSeek-V3 등이 이 구조를 써요.
작동 원리
핵심 아이디어는 간단해요. 모든 파라미터를 다 쓰는 게 아니라, 입력에 따라 일부 "전문가(Expert)"만 활성화시키는 거예요.
왜 효율적인가?
예를 들어 8개 전문가가 있고 top-2를 쓴다면? 전체 파라미터는 8배지만, 실제로는 25%만 쓰는 거예요! 그래서 큰 모델의 표현력을 가지면서도 계산량은 적은 거죠.
단점은 로드 밸런싱 문제가 있어요. 특정 전문가만 계속 선택되면 나머지는 학습이 안 돼요. 그래서 보조 손실(Auxiliary Loss)을 추가해서 전문가들이 고르게 선택되도록 유도해요.
언제 쓸까? 최신 초거대 언어 모델에서 쓰여요. 파라미터는 크지만 실제 연산은 적게 해야 할 때 좋죠!
3-4. 추론 모델 (Reasoning Models)
2024년에 OpenAI가 o1 모델을 발표하면서 새로운 패러다임이 열렸어요. "생각하는 AI"죠!
o1과 DeepSeek-R1
기존 LLM은 바로바로 답을 생성했어요. 하지만 o1은 내부적으로 "생각하는 과정"을 거쳐요. 수학 문제를 풀 때 중간 단계를 거치듯이요.
학습 방법은 강화 학습(Reinforcement Learning)이에요. 특히 PPO(Proximal Policy Optimization) 같은 기법을 써서, 올바른 추론 과정에 보상을 주고 학습시켜요.
DeepSeek-R1은 오픈소스로 나온 비슷한 모델인데요, 놀랍게도 수학이나 코딩 벤치마크에서 o1과 비슷한 성능을 보여줬어요!
왜 중요한가?
복잡한 추론이 필요한 문제(수학, 과학, 복잡한 코딩 등)에서 기존 모델보다 훨씬 나아요. 단순히 패턴을 외운 게 아니라 진짜로 "생각"하는 것처럼 문제를 풀죠.
단점은 느려요. 추론 단계가 많으니까요. 그리고 추론 과정이 보이지 않아서 블랙박스 문제가 더 심해요.
언제 쓸까? 복잡한 수학 문제, 과학 연구, 코드 디버깅, 복잡한 논리 추론이 필요한 작업에 써요!
4. 라이브러리와 도구들
실제로 이 모델들을 쓰려면 어떻게 할까요? 다행히 좋은 라이브러리들이 많아요!
Scikit-learn: 전통적 ML 모델(SVM, Random Forest, KNN 등) 전부 들어있어요. 입문자에게 최고!
XGBoost/LightGBM: 부스팅 알고리즘 전문. 캐글 필수템이죠.
TensorFlow/PyTorch: 딥러닝의 양대 산맥. PyTorch가 연구에선 더 인기 많고, TensorFlow는 프로덕션에 강해요.
Hugging Face Transformers: Transformer 기반 모델 전부 여기 있어요. BERT, GPT, T5 등등 수천 개 모델을 바로 쓸 수 있죠!
Diffusers: Stable Diffusion 등 Diffusion 모델들을 쉽게 쓸 수 있어요.
5. 실전 꿀팁 - 어떤 모델을 골라야 할까?
상황별로 추천해드릴게요!
데이터가 적을 때 (수백~수천 개)
- 선형 모델, SVM, 작은 Random Forest 추천
- 딥러닝은 과적합 위험
테이블 데이터 (행과 열)
- XGBoost, LightGBM, CatBoost가 최고
- 신경망보다 성능 좋은 경우 많음
이미지 데이터
- 작은 데이터셋: Transfer Learning (사전 학습 모델 활용)
- 큰 데이터셋: CNN 직접 학습
- 생성 작업: Diffusion Model
텍스트 데이터
- 분류/추출: BERT 계열
- 생성: GPT 계열
- 번역: Transformer (seq2seq)
시계열 데이터
- 전통적: ARIMA, Prophet
- 딥러닝: LSTM, Transformer
설명 가능성이 중요할 때
- 의사결정나무, 선형 모델, Random Forest
- XGBoost도 Feature Importance로 어느 정도 설명 가능
속도가 중요할 때
- 추론 속도: KNN(메모리에 올려놓으면), 작은 신경망
- 학습 속도: Random Forest(병렬화), LightGBM
최고 성능이 필요할 때
- 앙상블 (여러 모델 조합)
- XGBoost + 신경망 조합이 캐글에서 자주 우승
마무리하며
와... 진짜 길었죠? ㅠㅠ 하지만 이제 머신러닝 모델들의 전체 지도가 머릿속에 그려지지 않나요?
제일 중요한 건 어떤 모델도 만능이 아니다라는 거예요. 데이터의 특성, 문제의 종류, 계산 자원, 설명 가능성 요구사항 등을 종합적으로 고려해서 적절한 모델을 골라야 해요.
요즘 트렌드를 보면 Transformer와 Diffusion이 대세지만, 여전히 XGBoost가 테이블 데이터에서는 최고고, SVM이나 Random Forest도 충분히 쓸모 있어요. 상황에 맞는 도구를 고르는 게 진짜 실력이죠!
혹시 특정 모델에 대해 더 궁금한 점 있으면 댓글로 물어봐 주세요~ 같이 공부해요 ^_^
표로 정리하는 모델 비교
| 모델 | 데이터 타입 | 학습 속도 | 예측 속도 | 설명 가능성 | 성능 | 추천 상황 |
|---|---|---|---|---|---|---|
| 의사결정나무 | 테이블 | 빠름 | 빠름 | ★★★★★ | ★★☆☆☆ | 빠른 프로토타입, 설명 필요 |
| Random Forest | 테이블 | 보통 | 보통 | ★★★☆☆ | ★★★★☆ | 안정적 성능, 중간 데이터 |
| XGBoost | 테이블 | 보통 | 빠름 | ★★★☆☆ | ★★★★★ | 캐글 대회, 최고 성능 필요 |
| SVM | 테이블/텍스트 | 느림 | 보통 | ★★☆☆☆ | ★★★★☆ | 고차원 데이터, 작은 데이터 |
| KNN | 테이블 | 즉시 | 매우 느림 | ★★★★☆ | ★★★☆☆ | 간단한 분류, 추천 시스템 |
| K-Means | 테이블 | 빠름 | 빠름 | ★★★★☆ | ★★★☆☆ | 고객 세분화, 간단한 군집 |
| 기본 신경망 | 모든 타입 | 보통 | 빠름 | ★☆☆☆☆ | ★★★☆☆ | 비선형 관계, 중간 복잡도 |
| CNN | 이미지 | 느림 | 빠름 | ★☆☆☆☆ | ★★★★★ | 컴퓨터 비전 모든 작업 |
| RNN/LSTM | 시계열/텍스트 | 느림 | 보통 | ★☆☆☆☆ | ★★★☆☆ | 시퀀스 데이터 (구식) |
| Transformer | 텍스트/이미지 | 매우 느림 | 보통 | ★☆☆☆☆ | ★★★★★ | NLP 모든 작업, 최신 연구 |
| Diffusion | 이미지 | 매우 느림 | 매우 느림 | ★☆☆☆☆ | ★★★★★ | 이미지 생성, 예술 창작 |
#머신러닝 #딥러닝 #인공지능 #AI #MachineLearning #DeepLearning #데이터과학 #DataScience #XGBoost #RandomForest #Transformer #BERT #GPT #DiffusionModel #StableDiffusion #신경망 #NeuralNetwork #CNN #RNN #LSTM #SVM #의사결정나무 #DecisionTree #앙상블 #Ensemble #MoE #추론모델 #o1 #DeepSeekR1 #캐글 #Kaggle #파이썬 #Python #scikit-learn #PyTorch #TensorFlow #HuggingFace #2025년AI트렌드 #최신모델
'주식 예측 프로그램 > 머신러닝' 카테고리의 다른 글
| CNN으로 주식 예측이 가능할까? 딥러닝 초보자들이 꼭 알아야 할 진실 (0) | 2025.12.23 |
|---|---|
| CNN이 피처 간 중요도를 정해주지만 블랙박스인 이유 & SHAP가 그래서 뭔데? (0) | 2025.12.23 |
| 머신러닝 모델 돌릴 때 코드 짜면서 꼭 알아야 할 것들 (feat. 데이터 전처리의 함정들) (0) | 2025.12.23 |